Introduction
- Security operations is concerned with threats to a production operating environment.
- Threat agents can be internal or external actors, and ops security must account for both of these in order to be effective.
- Security operations is about people, data, media & hardware, as well as the threats associated with each of them.
Administrative security
- All organisations contain people, data, and the means for people to use the data.
- A fundamental aspect of operations security is ensuring that controls are in place to inhibit people either inadvertently or intentionally compromising the confidentiality, integrity, or availability of data, or the systems and media holding that data.
- Administrative security provides the means to control people’s operational access to data.
Administrative personnel controls
- Administrative personnel controls represent fundamental & key operations security concepts that permeate multiple domains.
Least privilege or minimum necessary access
- One of the most important concepts in all of information security is that of the principle of least privilege.
- The principle of least privilege dictates that persons have no more than the access that is strictly required for the performance of their duties.
- The principle of least privilege may also be referred to as the principle of minimum necessary access.
- Regardless of name, adherence to this principle is a fundamental tenet of security and should serve as a starting point for administrative security controls.
Need to know
- In organisations with extremely sensitive information that leverage mandatory access control (MAC), a basic determination of access is enforced by the system. The access determination is based upon clearance levels of subjects and classification levels of objects.
- Though the vetting process for someone accessing highly sensitive information is stringent, clearance level alone is insufficient when dealing with the most sensitive of information.
- An extension to the principle of least privilege in MAC environments is the concept of compartmentalisation. This is a method for enforcing need to know, which goes beyond the mere reliance upon clearance level and necessitates simply that someone requires access to information.
- Compartmentalisation is best understood by considering a highly sensitive military operation; while there may be a large number of individuals, some of whom might be of high rank, only a subset will “need to know” specific information. The others have no “need to know,” and therefore will not be granted access.
Separation of duties
- Separation of duties prescribes that multiple people are required to complete critical or sensitive transactions.
- The goal of separation of duties is to ensure that in order for someone to abuse their access to sensitive data or transactions, they must convince another party to act in concert.
- Collusion is the term used for the two parties conspiring to undermine the security of the transaction.
Job rotation
- Job rotation, also known as rotation of duties or rotation of responsibilities, provides an organisation with a means to reduce the risk associated with any one individual having too many privileges.
- Rotation of duties simply requires that one person does not perform critical functions or responsibilities for an extended period of time.
- There are multiple issues that rotation of duties can help to begin to address.
- One issue addressed by job rotation is the “hit by a bus” scenario.
- If the operational impact of the loss of an individual would be too great, then perhaps one way to reduce this impact would be to ensure that there is additional depth of coverage for this individual’s responsibilities.
Mandatory leave
- An additional operational control that is closely related to rotation of duties is that of mandatory leave, also known as forced vacation.
- Though there are various justifications for requiring employees to be away from work, the primary security considerations are similar to that addressed by rotation of duties: reducing or detecting personnel single points of failure, and detecting and deterring fraud.
Non-disclosure agreements
- A non-disclosure agreement (NDA) is a work-related contractual agreement ensuring that, prior to being given access to sensitive information or data, an individual or organisation appreciates their legal responsibility to maintain the confidentiality of that sensitive information.
- Job candidates, consultants, or contractors often sign NDAs before they are hired.
- NDAs are largely a directive control.
Background checks
- Background checks (also known as background investigations) are an additional administrative control commonly employed by many organisations.
- The majority of background investigations are performed as part of a pre-employment screening process.
- Some organisations perform cursory background investigations that include a criminal record check. Others perform more in-depth checks, such as verifying employment history, obtaining credit reports, and, in some cases, requiring the submission of a drug screening.
Forensics
- Digital forensics provides a formal approach to dealing with investigations and evidence with special consideration of the legal aspects of this process.
- The forensic process must preserve the “crime scene” and the evidence in order to prevent the unintentional violation of the integrity of either the data or its environment.
- A primary goal of forensics is to prevent unintentional modification of the system.
- Live forensics includes taking a bit-by-bit (binary) image image of physical memory, gathering details about running processes, and gathering network connection data.
Forensic media analysis
- In addition to the valuable data gathered during the live forensic capture, the main source of forensic data typically comes from binary images of secondary storage and portable storage devices such as hard disk drives, USB flash drives, CDs, DVDs, and possibly associated mobile phones and MP3 players.
Types of disk-based forensic data
- Allocated space: Portions of a disk partition that are marked as actively containing data.
- Unallocated space: Portions of a disk partition that do not contain active data. This includes portions that have never been allocated, as well as previously allocated portions that have been marked unallocated. If a file is deleted, the portions of the disk that held the deleted file are marked as unallocated and made available for use.
- Slack space: Data is stored in specific-sized chunks known as clusters, which are sometimes referred to as sectors or blocks. A cluster is the minimum size that can be allocated by a file system. If a particular file (or final portion of a file) does not require the use of the entire cluster, then some extra space will exist within the cluster. This leftover space is known as slack space; it may contain old data, or it can be used intentionally by attackers to hide information
- “Bad” blocks/clusters/sectors: Hard disks routinely end up with sectors that cannot be read due to some physical defect. The sectors marked as bad will be ignored by the operating system since no data could be read in those defective portions. Attackers could intentionally mark sectors or clusters as being bad in order to hide data within this portion of the disk.
Network forensics
- Network forensics is the study of data in motion, with a special focus on gathering evidence via a process that will support admission into a court of law.
- This means the integrity of the data is paramount, as is the legality of the collection process.
- Network forensics is closely related to network intrusion detection; the difference is the former focuses on legalities, while the later focuses on operations.
Embedded device forensics
- One of the greatest challenges facing the field of digital forensics is the proliferation of consumer-grade electronic hardware and embedded devices.
- While forensic investigators have had decades to understand and develop tools and techniques to analyse magnetic disks, newer technologies such as solid-state drives lack both forensic understanding and forensic tools capable of analysis.
eDiscovery
- Electronic discovery, or eDiscovery, pertains to legal counsel gaining access to pertinent electronic information during the pre-trial “discovery” phase of civil legal proceedings.
- The general purpose of discovery is to gather potential evidence that will allow for building a case.
- Electronic discovery differs from traditional discovery simply in that eDiscovery seeks ESI, or electronically stored information, which is typically acquired via a forensic investigation.
- While the difference between traditional discovery and eDiscovery might seem miniscule, given the potentially vast quantities of electronic data stored by organisations, eDiscovery can become logistically and financially cumbersome.
- Some of the challenges associated with eDiscovery stem from the seemingly innocuous backup policies of organisations. While long-term storage of computer information has generally been thought to be a sound practice, this data is discoverable.
- Discovery does not take into account whether ESI is conveniently accessible or transferrable. Appropriate data retention policies, in addition to software and systems designed to facilitate eDiscovery, can greatly reduce the burden on the organisation when required to provide ESI for discovery.
- When considering data retention policies, consider not only how long information should be kept, but also how long the information needs to be accessible to the organisation. Any data for which there is no longer a need should be appropriately purged according to the data retention policy.
Incident response management
- Because of the certainty of security incidents eventually impacting all organisations, there is a great need to be equipped with a regimented and tested methodology for identifying and responding to these incidents.
Methodology
- Many incident-handling methodologies treat containment, eradication, and recovery as three distinct steps.
- We will therefore cover eight steps, mapped to the current exam:
- Preparation
- Detection (identification)
- Response (containment)
- Mitigation (eradication)
- Reporting
- Recovery
- Remediation
- Lessons learned (post-incident activity, postmortem, or reporting)
- Other names for each step are sometimes used; the current exam lists a seven-step lifecycle but curiously omits the first step (preparation) in most incident handling methodologies. Perhaps preparation is implied, like the identification portion of AAA systems.
Preparation
- The preparation phase includes steps taken before an incident occurs.
- These include:
- training
- writing incident response policies and procedures
- providing tools such as laptops with sniffing software, crossover cables, original OS media, removable drives, etc.
- Preparation should include anything that may be required to handle an incident or that will make incident response faster and more effective.
- One preparation step is preparing an incident handling checklist, an example of which is shown below:
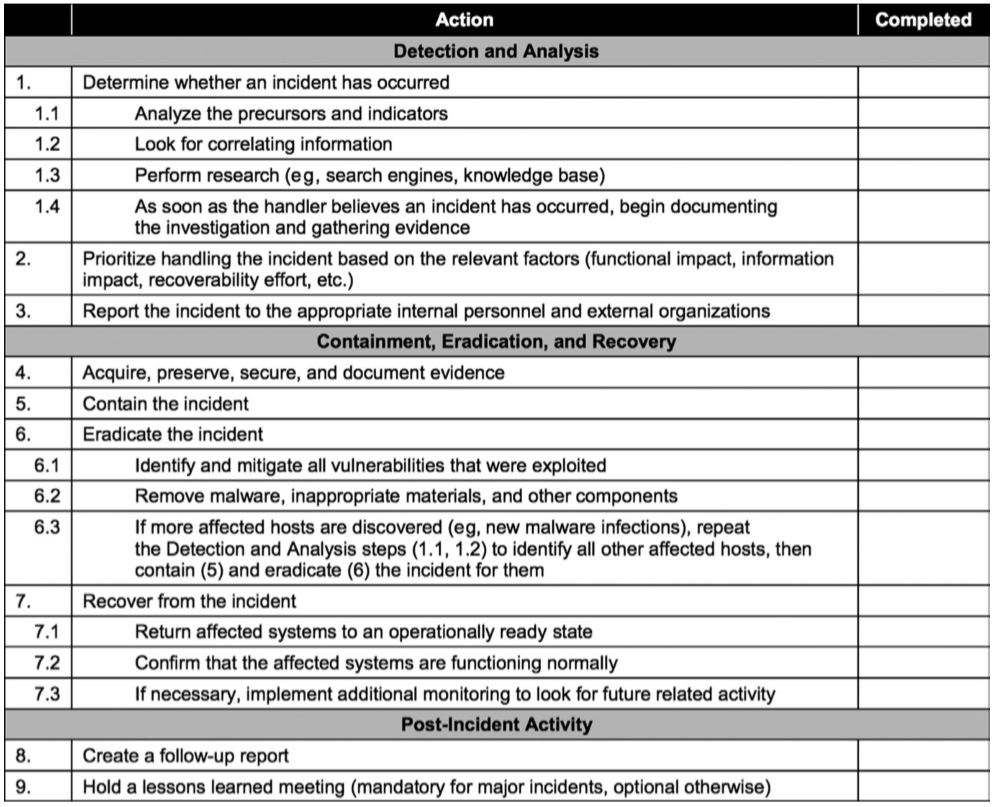
Detection (identification)
- One of the most important steps in the incident response process is the detection phase.
- Detection, also called identification, is the phase in which events are analysed in order to determine whether these events might comprise a security incident.
- Without strong detective capabilities built into the information systems, the organisation has little hope of being able to effectively respond to information security incidents in a timely fashion.
Response (containment)
- The response phase, or containment, of incident response is the point at which the incident response team begins interacting with affected systems and attempts to keep further damage from occurring as a result of the incident.
- Responses might include:
- taking a system off the network
- isolating traffic
- powering off the system
- …or other items to control both the scope and severity of the incident.
- This phase is also typically where a binary (bit-by-bit) forensic backup is made of systems involved in the incident.
- An important trend to understand is that most organisations will now capture volatile data before pulling the power plug on a system.
Mitigation (eradication)
- The mitigation (or eradication) phase involves the process of understanding the cause of the incident so that the system can be reliably cleaned and ultimately restored to operational status later in the recovery phase.
- In order for an organisation to recover from an incident, the cause of the incident must be determined. This is so that the systems in question can be returned to a known good state without significant risk of the compromise persisting or reoccurring.
- A common occurrence is for organisations to remove the most obvious piece of malware affecting a system and think that is sufficient; when in reality, the obvious malware may only be a symptom and the cause may still be undiscovered.
- Once the cause and symptoms are determined, the system needs to be restored to a good state and should not be vulnerable to further impact. This will typically involve either rebuilding the system from scratch or restoring from a known good backup.
Reporting
- The reporting phase of incident handling occurs throughout the process, beginning with detection.
- Reporting must begin immediately upon detection of malicious activity.
- It contains two primary areas of focus: technical and non-technical reporting.
- The incident handling teams must report the technical details of the incident as they begin the incident handling process, while maintaining sufficient bandwidth to also notify management of serious incidents.
- A common mistake is forgoing the latter while focusing on the technical details of the incident itself. Non-technical stake holders including business and mission owners must be notified immediately of any serious incident and kept up to date as the incident-handing process progresses.
Recovery
- The recovery phase involves cautiously restoring the system or systems to operational status.
- Typically, the business unit responsible for the system will dictate when the
system will go back online. - Remember to be mindful of the possibility that the infection, attacker, or other threat agent might have persisted through the eradication phase. For this reason, close monitoring of the system after it returns to production is necessary.
- Further, to make the security monitoring of this system easier, strong preference is given to the restoration of operations occurring during off-peak production hours.
Remediation
- Remediation steps occur during the mitigation phase, where vulnerabilities within the impacted system or systems are mitigated.
- Remediation continues after that phase and becomes broader. For example, if the root-cause analysis (discussed shortly) determines that a password was stolen and reused, local mitigation steps could include changing the compromised password and placing the system back online.
- Broader remediation steps could include requiring dual-factor authentication for all systems accessing sensitive data.
Lessons learned
- The goal of this phase is to provide a final report on the incident, which will be delivered to management.
- Important considerations for this phase should include:
- detailing ways in which the compromise could have been identified sooner
- how the response could have been quicker or more effective,
- which organisational shortcomings might have contributed to the incident
- what other elements might have room for improvement.
- Output from this phase feeds directly into continued preparation, where the lessons learned are applied to improving preparation for the handling of future incidents.
Root-cause analysis
- To effectively manage security incidents, root-cause analysis must be performed. This attempts to determine the underlying weakness or vulnerability that allowed the incident to be realised.
- Without successful root-cause analysis, the victim organisation could recover systems in a way that still includes the particular weaknesses exploited by the adversary causing the incident.
- In addition to potentially recovering systems with exploitable flaws, another unfortunate possibility includes reconstituting systems from backups or snapshots that have already been compromised.
Operational preventive & detective controls
- Many preventive & detective controls require higher operational support and are the focus of daily operations security
- For example, routers and switches tend to have comparatively low operational expenses (OpEx).
- Other controls, such as NIDS and NIPS, antivirus, and application whitelisting have comparatively higher OpEx and are a focus in this domain.
Intrusion detection & prevention systems
- An intrusion detection system (IDS) detects malicious actions, including violations of policy.
- An intrusion prevention system (IPS) also prevents malicious actions. There are two basic types of IDSs and IPSs: network based and host based.
Event types
- There are four types of IDS/IPS events: true positive, true negative, false positive, and false negative. To illustrate these events, we will use two streams of traffic: a worm, and a user surfing the Web.
- True positive: A worm is spreading on a trusted network; NIDS alerts
- True negative: User surfs the Web to an allowed site; NIDS is silent
- False positive: User surfs the Web to an allowed site; NIDS alerts
- False negative: A worm is spreading on a trusted network; NIDS is silent
- The goal is to have only true positives and true negatives, but most IDSs have false positives and false negatives as well.
- False positives waste time and resources, as staff spend time investigating non-malicious events.
- A false negative is arguably the worst-case scenario because malicious network traffic is neither detected nor prevented.
NIDS & NIPS
- A network-based intrusion detection system (NIDS) detects malicious traffic on a network.
- NIDS usually require promiscuous network access in order to analyse all traffic, including all unicast traffic.
- NIDS are passive devices that do not interfere with the traffic they monitor; the diagram below shows a typical NIDS architecture.
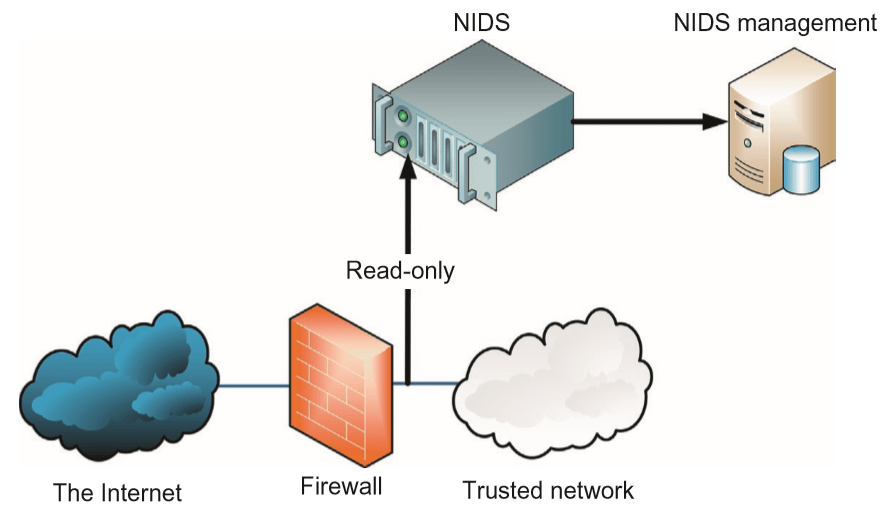
- The NIDS sniffs the internal interface of the firewall in read-only mode and sends alerts to a NIDS Management server via a different (i.e. read/write) network interface.
- The difference between a NIDS and a NIPS is that the NIPS alters the flow of network traffic.
- There are two types of NIPS: active response and inline.
- Architecturally, an active response NIPS is like the NIDS illustrated above; the difference is that the monitoring interface is read/write.
- The active response NIPS may “shoot down” malicious traffic via a variety of methods, including forging TCP RST segments to source or destination (or both), or sending ICMP port, host, or network unreachable to source.
- An inline NIPS operates in series (hence “in line”) with traffic, acting as a Layer 3–7 firewall by passing or allowing traffic, as shown below.
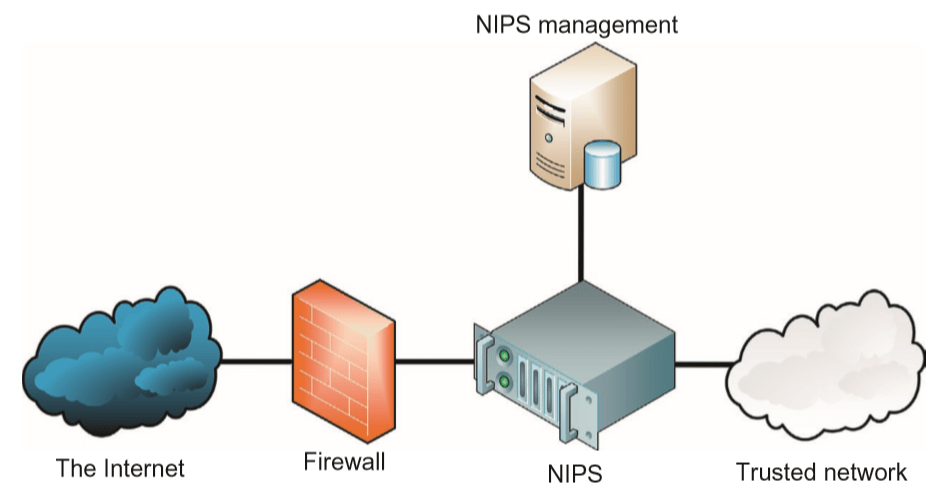
- Note that a NIPS provides defence-in-depth protection in addition to a firewall; it is not typically used as a replacement.
- Also, a false positive by a NIPS is more damaging than one by a NIDS because legitimate traffic is denied, which may cause production problems.
- A NIPS usually has a smaller set of rules compared to a NIDS for this reason, and only the most trustworthy rules are used.
- A NIPS is not a replacement for a NIDS; many networks use both.
HIDS & HIPS
- Host-based intrusion detection systems (HIDS) and host-based intrusion prevention systems (HIPS) are cousins to NIDS and NIPS.
- They process information within the host and may process network traffic as it enters the host, but the exam’s focus is usually on files and processes.
Security information & event management (SIEM)
- Correlation of security-relevant data is the primary utility provided by Security Information and Event Management (SIEM).
- The goal of data correlation is to better understand the context so as to arrive at a greater understanding of risk within the organisation due to activities that are noted across various security platforms.
- While SIEMs typically come with some built-in alerts that look for particular correlated data, custom correlation rules are typically created to augment the built-in capabilities
Data loss prevention
- As prominent and high-volume data breaches continue, the desire for solutions designed to address data loss has grown.
- Data loss prevention (DLP) is a class of solutions that are tasked specifically with trying to detect or preferably prevent data from leaving an organisation in an unauthorised manner.
- The approaches to DLP vary greatly. One common approach employs network-oriented tools that attempt to detect and/or prevent sensitive data being exfiltrated in cleartext.
- The above approach does nothing to address the potential for data exfiltration over an encrypted channel. Dealing with the potential for encrypted exfiltration typically requires endpoint solutions to provide visibility prior to encryption.
Endpoint security
- Because endpoints are the targets of attacks, preventive and detective capabilities on the endpoints themselves provide a layer beyond network-centric security devices.
- Modern endpoint security suites often encompass a variety of products beyond simple antivirus software. These suites can increase the depth of security countermeasures well beyond the gateway or network perimeter.
- An additional benefit offered by endpoint security products is their ability to provide preventive and detective control even when communications are encrypted all
the way to the endpoint in question. - Typical challenges associated with endpoint security are around volume; vast number of products/systems must be managed, while significant amounts of data must be analysed and potentially retained.
Antivirus
- The most commonly deployed endpoint security product is antivirus software.
- Antivirus is one of many layers of endpoint defence-in-depth security.
- Although antivirus vendors often employ heuristic or statistical methods for malware detection, the predominant means of detecting malware is still signature based.
Application whitelisting
- Application whitelisting is a more recent addition to endpoint security suites. The primary focus of application whitelisting is to determine in advance which binaries are considered safe to execute on a given system.
- Once this baseline has been established, any binary attempting to run that is not on the list of “known-good” binaries is prevented from doing so.
- A weakness of this approach is when a “known-good” binary is exploited by an attacker and used maliciously.
Removable media controls
- The need for better control of removable media has been felt on two fronts in particular.
- First, malware-infected removable media inserted into an organisation’s computers has been a method for compromising otherwise reasonably secure organisations.
- Second, the volume of storage that can be contained in something the size of a fingernail is astoundingly large and has been used to surreptitiously exfiltrate sensitive data.
Disk encryption
- Another endpoint security product found with increasing regularity is disk encryption software.
- Full disk encryption, also called whole disk encryption, encrypts an entire disk. This is superior to partially encrypted solutions, such as encrypted volumes, directories, folders, or files. The problem with the latter approach is the risk of leaving sensitive data on an unencrypted area of the disk.
Asset management
- A holistic approach to operational information security requires organisations to
focus on systems as well as people, data, and media. - Systems security is another vital component to operational security, and there are specific controls that can greatly improve security throughout the system’s lifecycle.
Configuration management
- Basic configuration management practices associated with system security will involve tasks such as:
- disabling unnecessary services
- removing extraneous programs
- enabling security capabilities such as firewalls, antivirus, and IDS/IPS systems
- configuring security and audit logs.
Baselining
- Security baselining is the process of capturing a snapshot of the current system security configuration.
- Establishing an easy means for capturing the current system security configuration can be extremely helpful in responding to a potential security inciden.t
Vulnerability management
- Vulnerability scanning is a way to discover poor configurations and missing patches in an environment.
- The term vulnerability management is used rather than just vulnerability scanning in order to emphasise the need for management of the vulnerability information.
- The remediation or mitigation of vulnerabilities should be prioritised based on both risk to the organisation and ease of remediation procedures.
Zero-day vulnerabilities/exploits
- A zero-day vulnerability is a vulnerability that is known before the existence of a patch.
- Zero-day (or 0-day) vulnerabilities are becoming increasingly important as attackers are becoming more skilled in discovery, and disclosure of zero-day vulnerabilities is being monetised.
- A zero-day exploit refers to the existence of exploit code for a vulnerability that has yet to be patched.
Change management
- In order to maintain consistent and known operational security, a regimented change management or change control process needs to be followed.
- The purpose of this process is to understand, communicate, and document any changes; the primary goal is to understand, control, and avoid direct or indirect negative impact that the change might impose.
- The general flow of the change management process includes:
- Identifying a change
- Proposing a change
- Assessing the risk associated with the change
- Testing the change
- Scheduling the change
- Notifying impacted parties of the change
- Implementing the change
- Reporting results of the change implementation
- All changes must be closely tracked and auditable; a detailed change record should be kept.
- Some changes can destabilise systems or cause other problems; change management auditing allows operations staff to investigate recent changes in the event of an outage or problem.
- Audit records also allow auditors to verify that change management policies and procedures have been followed.
Continuity of operations
- Continuity of operations is principally concerned with availability.
Service level agreements
- A service level agreement (SLA) stipulates all expectations regarding the behavior of the department or organisation that is responsible for providing services, and the quality of those services.
- SLAs will often dictate what is considered acceptable regarding things such as bandwidth, time to delivery, response times, etc.
Fault tolerance
- In order for systems and solutions within an organisation to be able to continually provide operational availability, they must be implemented with fault tolerance in mind.
- Availability is not solely focused on system uptime requirements; it requires that data be accessible in a timely fashion as well.
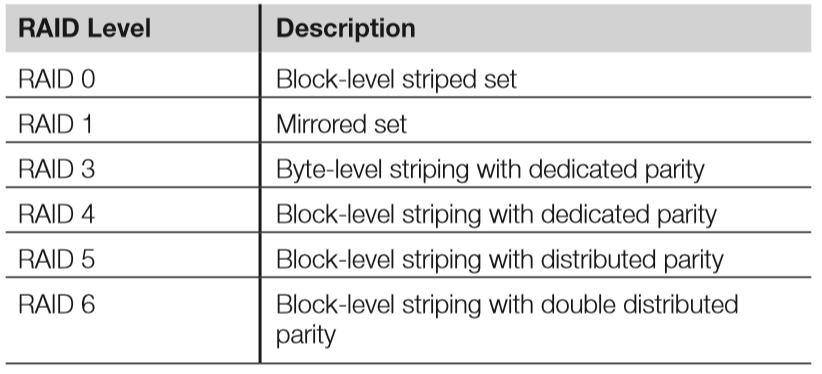
RAID
- Even if only one full backup tape is needed for recovery of a system due to a hard disk failure, the time to recover a large amount of data can easily exceed the recovery time dictated by the organisation.
- The goal of a redundant array of inexpensive disks (RAID) is to help mitigate the risk associated with hard disk failures.
- Three critical RAID terms are mirroring, striping & parity.
- Mirroring achieves full data redundancy by writing the same data to multiple hard disks.
- Striping focuses on increasing read and write performance by spreading data across multiple hard disks. Writes can be performed in parallel across multiple disks rather than serially on one disk. This parallelisation increases performance but does not contribute to data redundancy.
- Parity achieves data redundancy without incurring the same degree of cost as that of mirroring, in terms of disk usage and write performance.
- There are various RAID levels that consist of different approaches to disk array configurations, as summarised below.
- Warning: While the ability to quickly recover from a disk failure is a goal of RAID, there are configurations that do not have reliability as a capability. For the exam, understand that not all RAID configurations provide additional reliability.
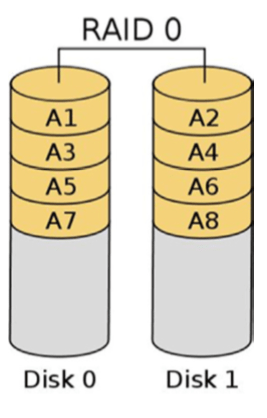
RAID 0: Striped set
- RAID 0, as shown below, employs striping to increase the performance of reads & writes.
- Striping offers no data redundancy, so RAID 0 is a poor choose if recovery of data is critical.
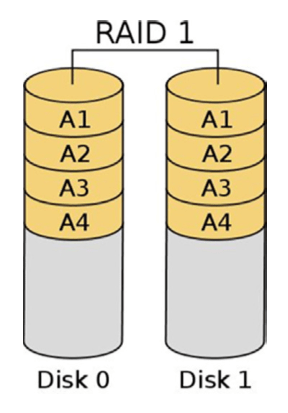
RAID 1: Mirrored set
- RAID 1 creates/writes an exact duplicate of all data to an additional disk, as shown below.
RAID 2: Hamming code
- RAID 2 is a legacy technology that requires either 14 or 39 hard disks and a specially designed hardware controller, making RAID 2 cost prohibitive.
- RAID 2 stripes at the bit level.
RAID 3: Striped set with dedicated parity (byte level)
- Striping is desirable due to the performance gains associated with spreading data across multiple disks. However, striping alone is not as desirable due to the lack of redundancy.
- With RAID 3, data at the byte level is striped across multiple disks, but an additional disk is leveraged for storage of parity information, which is used for recovery in the event of a failure.
RAID 4: Striped set with dedicated parity (block level)
- RAID 4 provides the same functionality as RAID 3, but stripes data at the block level instead of byte level.
- Like RAID 3, RAID 4 employs a dedicated parity drive (rather than having parity data distributed among all disks, as in RAID 5)
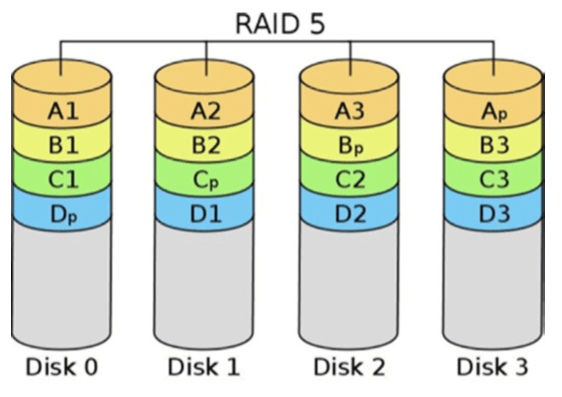
RAID 5: Striped set with distributed parity
- One of the most popular RAID configurations is that of RAID 5, striped set with
distributed parity (shown below). - Like RAIDs 3 and 4, RAID 5 writes parity information that is used for recovery purposes.
- RAID 5 writes at the block level, like RAID 4. However, unlike RAIDs 3 and 4, which require a dedicated disk for parity information, RAID 5 distributes the parity information across multiple disks.
- One of the reasons for RAID 5’s popularity is that the disk cost for redundancy is potentially lower than that of a mirrored set, while at the same time gaining performance improvements associated with RAID 0.
- RAID 5 allows for data recovery in the event that any one disk fails.
RAID 6: Striped set with dual-distributed parity
- While RAID 5 accommodates the loss of any one drive in the array, RAID 6 can allow for the failure of two drives and still function.
- This redundancy is achieved by writing the same parity information to two different disks.
RAID 10
- RAID 10, or more properly RAID 1+0, is an example of what is known as nested RAID or multi-RAID, which simply means that one standard RAID is encapsulated within another.
- With RAID 10, the configuration is that of a striped set of mirrors.
System redundancy
Redundant hardware & systems
- Many systems can provide internal hardware redundancy of components that are extremely prone to failure.
- The most common example of this built-in redundancy is systems or devices that have redundant onboard power in the event of a power supply failure.
- Sometimes systems simply have field replaceable modular versions of commonly failing components. Though physically replacing a power supply might increase downtime, having an inventory of spare modules to service all of the datacenter’s servers would be less expensive than having all servers configured with an installed redundant power supply.
- Redundant systems (i.e. alternative systems) make entire systems available in case of failure of the primary system.
High-availability clusters
- A high-availability (HA) cluster, also called a failover cluster, uses multiple systems that are already installed, configured, and plugged in, so that if a failure causes one of the systems to fail, another can be seamlessly leveraged to maintain the availability of the service or application being provided.
- Each member of an active-active HA cluster actively processes data in advance of a failure. This is commonly referred to as load balancing.
- Having systems in an active-active or load-balancing configuration is typically more costly than having the systems in an active-passive or hot standby configuration, in which the backup systems only begin processing when a failure is detected.
BCP & DR overview and process
- The terms and concepts associated with Business Continuity and Disaster Recovery Planning are very often misunderstood.
- Clear understanding of what is meant by both terms, and what they entail, is critical.
Business continuity planning
- Though many organisations will use the phrases Business Continuity Planning (BCP) or Disaster Recovery Planning (DRP) interchangeably, they are two distinct disciplines.
- Though both types of planning are essential to the effective management of disasters and other disruptive events, their goals are different.
- The overarching goal of BCP is to ensure that the business will continue to operate before, throughout, and after a disaster event is experienced.
- The focus of BCP is on the business as a whole, ensuring that those critical services or functions the business provides or performs can still be carried out both in the wake of a disruption and after the disruption has been weathered.
Disaster recovery planning
- The Disaster Recovery Plan (DRP) provides a short-term plan for dealing with specific IT-oriented disruptions.
- Mitigating a malware infection that shows risk of spreading to other systems is an example of a specific IT-oriented disruption that a DRP would address.
- The DRP focuses on efficiently attempting to mitigate the impact of a disaster by preparing the immediate response and recovery of critical IT systems.
- DRP is considered tactical rather than strategic, and provides a means for immediate response to disasters.
Relationship between BCP & DRP
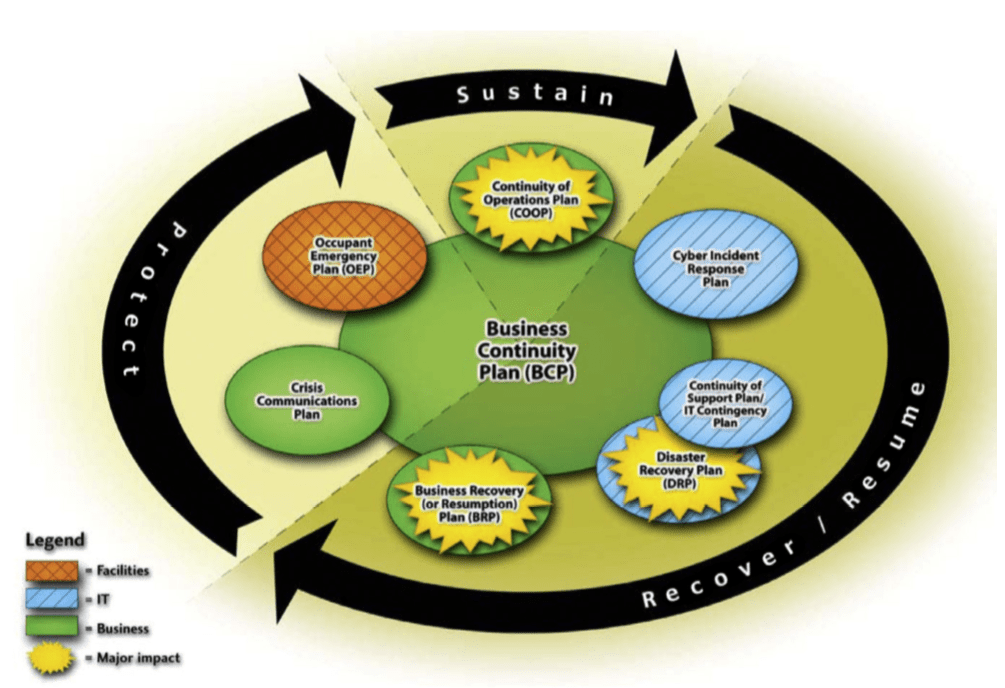
- The BCP is an umbrella plan that includes multiple specific plans, most importantly the DRP.
- DRP serves as a subset of the overall BCP, which would be doomed to fail if it did not contain a tactical method for immediately dealing with disruption of information systems.
- The figure below visual means for understanding the inter-relatedness of BCP and DRP, as well as some related plans.
Disasters or disruptive events
- Given that BCP and DRP are created because of the potential of disasters impacting operations, it is vital that organisations understand the nature of disasters and disruptive events.
- The three common ways of categorising the causes for disasters are derived from whether the threat agent is natural, human or environmental:
- Natural — This category includes threats such as earthquakes, hurricanes, tornadoes, floods, and some types of fires. Historically, natural disasters have provided some of the most devastating disasters to which an organsation must respond.
- Human — The human category of threats represents the most common source of disasters. Human threats can be further classified by whether they constitute an intentional or unintentional threat.
- Environmental — Threats focused on information systems or data centre environments; includes items such as power issues (blackout, brownout, surge, spike, etc.), system component or other equipment failures, and application or software flaws.
- The analysis of threats and the determination of the associated likelihood of those threats are important parts of the BCP and DRP process. Below is a quick summary of some of the disaster events and what type of disaster they constitute.
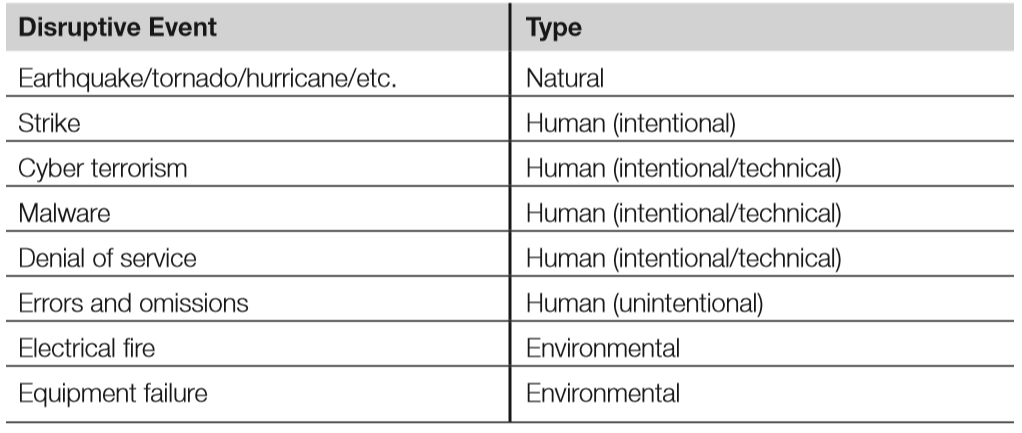
- Types of disruptive events include:
- Errors and omissions: Typically considered the most common source of disruptive events. This type of threat is caused by humans who unintentionally serve as a source of harm.
- Natural disasters: These include earthquakes, hurricanes, floods, tsunamis, etc.
- Electrical or power problems: Loss of power may cause availability issues, as well as integrity issues due to corrupted data.
- Temperature and humidity failures: These may damage equipment due to overheating, corrosion, or static electricity.
- Warfare, terrorism, and sabotage: These threats can vary dramatically based on geographic location, industry, and brand value, as well as the interrelatedness with other high-value target organisations.
- Financially motivated attackers: Attackers who seek to make money by attacking victim organisations, e.g. by exfiltration of cardholder data, identity theft, pump-and-dump stock schemes, bogus anti-malware tools, corporate espionage, and others.
- Personnel shortages: May be caused by strikes, pandemics, or transportation issues. A lack of staff may lead to operational disruption.
The disaster recovery process
- Having discussed the importance of BCP and DRP as well as examples of threats that justify this degree of planning, we will now focus on the fundamental steps involved in recovering from a disaster.
Respond
- In order to begin the disaster recovery process, there must be an initial response that begins the process of assessing the damage.
- Speed is essential during this initial assessment, which will determine if the event in question constitutes a disaster.
Activate team
- If a disaster is declared, then the recovery team needs to be activated. Depending on the scope of the disaster, this communication could prove extremely difficult.
- The use of call trees (detailed later) can help to facilitate this process to ensure that members can be activated as smoothly as possible.
Communicate
- One of the most difficult aspects of disaster recovery is ensuring that consistent & timely status updates are communicated back to the central team managing the response and recovery process.
- This communication must often occur out-of-band, meaning that the typical communication method of an office phone will generally not be a viable option.
- In addition to communication of internal status regarding the recovery activities, the organisation must be prepared to provide external communications, which involves disseminating details to the public.
Assess
- Though an initial assessment was carried out during the initial response portion of the disaster recovery process, a more detailed and thorough assessment will be performed by the disaster recovery team.
- The team will proceed to assessing the extent of the damage to determine the proper steps necessary to ensure the organisation’s ability to meet its mission.
Reconstitution
- The primary goal of the reconstitution phase is to successfully recover critical business operations at either a primary or secondary site.
- If an alternate site is leveraged, adequate safety and security controls must be in place in order to maintain the expected degree of security the organisation typically employs; the use of an alternate computing facility for recovery should not expose the organisation to further security incidents.
- In addition to the recovery team‘s efforts in reconstituting critical business functions at an alternate location, a salvage team will be employed to begin the recovery process at the primary facility that experienced the disaster.
- Ultimately, the expectation is that unless it is wholly unwarranted given the circumstances, the primary site will be recovered and that the alternate facility’s operations will “fail back” or be transferred again to the primary center of operations.
Developing a BCP/DRP
- Developing BCP/DRP is vital for an organisation’s ability to respond and recover from an interruption in normal business functions or catastrophic event.
- In order to ensure that all planning has been considered, the BCP/DRP has a specific set of requirements to review and implement.
- Below are listed these high-level steps, according to NIST SP800-34 (NIST’s Contingency Planning Guide for Federal Information Systems), to achieving a sound, logical BCP/DRP.
Project initiation
- In order to develop the BCP/DRP, the scope of the project must be determined & agreed upon.
- The project initiation step involves seven distinct milestones, as listed below:
- Develop the contingency planning policy statement: A formal department or agency policy provides the authority and guidance necessary to develop an effective contingency plan.
- Conduct the BIA: The BIA helps identify and prioritise critical IT systems and components. A template for developing the BIA is also provided to assist the user.
- Identify preventive controls: Measures taken to reduce the effects of system disruptions can increase system availability and reduce contingency life-cycle costs.
- Develop recovery strategies: Thorough recovery strategies ensure that the system may be recovered quickly and effectively following a disruption.
- Develop an IT contingency plan: The contingency plan should contain detailed guidance and procedures for restoring a damaged system.
- Plan testing, training, and exercises: Testing the plan identifies planning gaps, whereas training prepares recovery personnel for plan activation; both activities improve plan effectiveness and overall agency preparedness.
- Plan maintenance: The plan should be a living document that is updated regularly to remain current with system enhancements
Assessing the critical state
- Assessing the critical state can be difficult, because determining which pieces of the IT infrastructure are critical depends solely on the how it supports the users within the organisation.
- For example, without consulting all of the users, a simple mapping program may not seem to be a critical asset. However, if there is a user group that drives trucks and makes deliveries for business purposes, this mapping software may be critical for them to schedule pickups and deliveries.
Conduct BIA
- Business impact analysis (BIA) is the formal method for determining how a disruption to the IT system(s) of an organisation will impact requirements, processes, and interdependencies with respect to the business mission.
- It aims to identify and prioritise critical IT systems and components, which enables the BCP/DRP project manager to fully characterise the IT contingency requirements and priorities.
- The objective is to correlate each IT system component with the critical service it supports. It also aims to quantify the consequence of a disruption to the system component and how that will affect the organisation.
- The primary goal of the BIA is to determine the Maximum Tolerable Downtime (MTD) for a specific IT asset. This will directly impact what disaster recovery solution is chosen.
Identify critical assets
- The critical asset list is a list of those IT assets that are deemed business-essential by the organisation.
- These systems’ DRP/BCP must have the best available recovery capabilities assigned to them.
Conduct BCP/DRP-focused risk assessment
- The BCP/DRP-focused risk assessment determines what risks are inherent to which IT assets.
- A vulnerability analysis is also conducted for each IT system and major application. This is done because most traditional BCP/DRP evaluations focus on physical security threats, both natural and human.
Determine MTD
- The primary goal of the BIA is to determine the MTD (maximum tolerable downtime), which describes the total time a system can be inoperable before an organisation is severely impacted. MTD is comprised of two metrics: the Recovery Time Objective (RTO), and the Work Recovery Time (WRT) – described later.
- Depending on the business continuity framework that is used, other terms may be substituted for MTD. These include Maximum Allowable Downtime, Maximum Tolerable Outage, and Maximum Acceptable Outage.
Failure & recovery metrics
- A number of metrics are used to quantify how frequently systems fail, how long a system may exist in a failed state, and the maximum time to recover from failure.
- These metrics include the Recovery Point Objective (RPO), RTO, WRT, Mean Time Between Failures (MTBF), Mean Time to Repair (MTTR), and Minimum Operating Requirements (MOR).
Recovery point objective (RPO)
- The RPO is the amount of data loss or system inaccessibility (measured in time) that an organisation can withstand.
- e.g. If you perform weekly backups, someone made a decision that your company could tolerate the loss of a week’s worth of data. If backups are performed on Saturday evenings and a system fails on Saturday afternoon, you have lost the entire week’s worth of data. This is the RPO; in this case, the RPO is 1 week.
- The RPO represents the maximum acceptable amount of data/work loss for a given process because of a disaster or disruptive event
Recovery time objective (RTO) & work recovery time (WRT)
- The RTO describes the maximum time allowed to recover business or IT systems. RTO is also called the systems recovery time. This is one part of MTD; once the
system is physically running, it must be configured. - WRT describes the time required to configure a recovered system.
- Downtime consists of two elements, the systems recovery time and the WRT. Therefore, MTD = RTO + WRT.
Mean time between failures (MTBF)
- MTBF quantifies how long a new or repaired system will run before failing.
- It is typically generated by a component vendor and is largely applicable to hardware, as opposed to applications and software.
Mean time to repair (MTTR)
- The MTTR describes how long it will take to recover a specific failed system. It is the best estimate for reconstituting the IT system so that business continuity may occur.
Minimum operating requirements (MOR)
- MORs describe the minimum environmental and connectivity requirements in order to operate computer equipment.
- It is important to determine and document what the MOR is for each IT-critical asset because in the event of a disruptive event or disaster, proper analysis can be conducted quickly to determine if the IT assets will be able to function in the emergency environment.
Identify preventive controls
- Preventive controls can prevent disruptive events from having an impact.
- For example, HVAC systems are designed to prevent computer equipment from overheating & failing.
- The BIA will identify some risks that may be mitigated immediately; this is another advantage of performing BCP/DRP, as it can improve your security, even if no disaster occurs.
Recovery strategy
- Once the BIA is complete, the BCP team knows the MTD. This metric, as well as others including the RPO and RTO, is used to determine the recovery strategy.
- A cold site cannot be used if the MTD is 12 hours, for example. As a general rule, the shorter the MTD, the more expensive the recovery solution will be.
Redundant site
- A redundant site is an exact production duplicate of a system that has the capability to seamlessly operate all necessary IT operations without loss of services to the end user of the system.
- A redundant site receives data backups in real time so that in the event of a disaster, the users of the system have no loss of data. It is a building configured exactly like the primary site, and is the most expensive recovery option because it effectively more than doubles the cost of IT operations.
- To be fully redundant, a site must have real-time data backups to the redundant system and the end user should not notice any difference in IT services or operations in the event of a disruptive event.
Hot site
- A hot site is a location that an organisation may relocate to following a major disruption or disaster.
- It is a data centre with a raised floor, power, utilities, computer peripherals, and fully configured computers.
- The hot site will have all necessary hardware and critical applications data mirrored in real time.
- A hot site will have the capability to allow the organisation to resume critical operations within a very short period of time, sometimes in less than an hour.
- It is important to note the difference between a hot site and a redundant site. Hot sites can quickly recover critical IT functionality; it may even be measured in minutes instead of hours. However, a redundant site will appear as operating normally to the end user, no matter what the state of operations is for the IT program.
- A hot site has all the same physical, technical, and administrative controls implemented as at the production site.
Warm site
- A warm site has some aspects of a hot site; for example, readily accessible hardware and connectivity, but it will have to rely upon backup data in order to reconstitute a system after a disruption.
- It is a data centre with a raised floor, power, utilities, computer peripherals, and fully configured computers.
Cold site
- A cold site is the least expensive recovery solution to implement. It does not include backup copies of data, nor does it contain any immediately available hardware.
- After a disruptive event, a cold site will take the longest amount of time of all recovery solutions to implement and restore critical IT services for the organisation.
- Especially in a disaster area, it could take weeks to get vendor hardware shipments in place, so organisations using a cold site recovery solution will have to be able to withstand a significantly long MTD measured in weeks, not days.
- A cold site is typically a data centre with a raised floor, power, utilities, and physical security, but not much beyond that.
Reciprocal agreements
- A reciprocal agreement is a bidirectional agreement between two organisations in which one organisation promises another that it can move in and share space if it experiences a disaster.
- It is documented in the form of a contract written to gain support from outside organisations in the event of a disaster.
- They are also referred to as mutual aid agreements and they are structured so that each organisation will assist the other in the event of an emergency.
Mobile site
- Mobile sites, or rolling sites, are basically data centres on wheels: towable trailers that contain racks of computer equipment, as well as HVAC, fire suppression, and physical security.
- They are a good fit for disasters such as a data centre flood, where the data centre is damaged but the rest of the facility and surrounding property are intact.
- They may be towed on-site, supplied with power and a network, and brought online.
Related plans
- As discussed previously, the BCP is an umbrella plan encompassing other plans
- The table below, from NIST SP 800-34, summarises these:
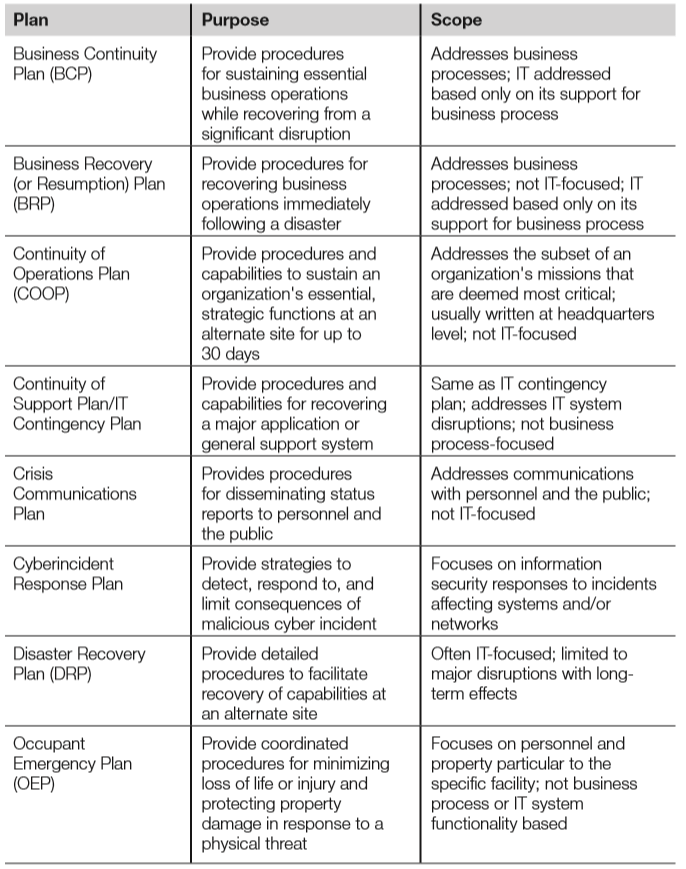
Continuity of operations plan (COOP)
- The COOP describes the procedures required to maintain operations during a disaster
- This includes transfer of personnel to an alternate DR site, and operations of that site
Business recovery plan (BRP)
- The BRP, also known as the Business Resumption Plan, details the steps required to restore normal business operations after recovering from a disruptive event.
- This may include switching operations from an alternate site back to a repaired primary site.
- The BRP picks up when the COOP is complete. This plan is narrow and focused: the BRP is sometimes included as an appendix to the BCP.
Continuity of support plan
- The Continuity of Support Plan focuses narrowly on support of specific IT systems and applications.
- It is also called the IT Contingency Plan, emphasising IT over general business support.
Cyberincident response plan
- The Cyberincident Response Plan is designed to respond to disruptive cyberevents, including network-based attacks, worms, computer viruses, Trojan horses, etc., that have the potential to disrupt networks.
- Loss of network connectivity alone may constitute a disaster for many organisations.
Occupant emergency plan (OEP)
- The OEP provides the response procedures for occupants of a facility in the event of a situation posing a potential threat to the health and safety of personnel, the environment, or property (such as a fire, hurricane, criminal attack, or a medical emergency.)
- This plan is facilities-focused, as opposed to business- or IT-focused.
- The OEP is focused on safety and evacuation, and should describe specific safety drills, including evacuation or fire drills.
- Specific safety roles should be described, including safety warden and meeting point leader, as described in Domain 3.
Crisis management plan (CMP)
- The CMP is designed to provide effective coordination among the managers of the organisation in the event of an emergency or disruptive event.
- The CMP details the actions that management must take to ensure that life and safety of personnel and property are immediately protected in case of a disaster.
Crisis communications plan
- A critical component of the CMP is the Crisis Communications Plan, which is sometimes simply called the communications plan; a plan for communicating to staff and the public in the event of a disruptive event.
- Instructions for notifying the affected members of the organisation are an integral part to any BCP/DRP.
- It is often said that bad news travels fast. Also, in the event of a post-disaster “information vacuum”, bad information will often fill the void.
- Public relations professionals understand this risk and know to consistently give the organisation’s “official story,” even when there is little to say.
- All communication with the public should be channelled via senior management or the PR team.
Call trees
- A key tool leveraged for staff communication by the Crisis Communications Plan is the Call Tree, which is used to quickly communicate news throughout an organisation without overburdening any specific person.
- The call tree works by assigning each employee a small number of other employees they are responsible for calling in an emergency event.
- For example, the organisation’s president may notify his board of directors of an emergency situation and they, in turn, will notify their top-tier managers. The top-tier managers will then call the people they have been assigned to call. The call tree continues until all affected personnel have been contacted.
- The call tree is most effective when there is a two-way reporting of successful communication. For example, each member of the board of directors would report back to the president when each of their assigned call tree recipients had been contacted and had made contact with their subordinate personnel.
- Remember that mobile phones and landlines may become congested or unusable during a disaster; the call tree should contain alternate contact methods in case the primary methods are unavailable.
Emergency Operations Centre
- The Emergency Operations Centre is the command post established during or just after an emergency event.
- Placement of the EOC will depend on resources that are available.
- For larger organisations, the EOC may be a long distance away from the physical emergency; however, protection of life and personnel safety is always of the utmost importance.
Backups & availability
- Though many organisations are diligent in the process of creating backups, verification of recoverability from those backup methods is at least as
important, but is often overlooked. - When the detailed recovery process for a given backup solution is thoroughly reviewed, some specific requirements will become obvious.
- One of the most important points to make when discussing backup with respect to disaster recovery and business continuity is to ensure that critical backup media is stored offsite.
- Further, that offsite location should be situated such that, during a disaster event, the organisation can efficiently access the media with the purpose of taking it to a primary or secondary recovery location.
Hard-copy data
- In the event that there is a disruptive event, such as a natural disaster that disables the local power grid, and power dependency is problematic, there is the potential to operate the organisation’s most critical functions using only hard-copy data.
- Hard-copy data is any data that are accessed through reading or writing on paper rather than processing through a computer system.
Electronic backups
- Electronic backups are archives that are stored electronically and can be retrieved in case of a disruptive event or disaster.
- Choosing the correct data backup strategy is dependent upon how users store data, the availability of resources and connectivity, and what the ultimate recovery goal is for the organisation.
- Preventative restoration is a recommended control; that is, restoring data to test the validity of the backup process.
- If a reliable system, such as a mainframe, copies data to tape every day for years, what assurance does the organisation have that the process is working? Do the tapes and the data they contain have integrity?
Full backups
- A full backup means that every piece of data is copied and stored on the backup repository.
- Conducting a full system backup is time consuming and a strain on bandwidth and resources. However, they will ensure that any and all necessary data is protected.
Incremental backups
- Incremental backups archive data that has changed since the last full or incremental backup.
- For example, a site performs a full backup every Sunday, with daily incremental backups from Monday through Saturday. If data is lost after the Wednesday incremental backup, four tapes are required for restoration: the Sunday full backup, as well as the Monday, Tuesday, and Wednesday incremental backups.
Differential backups
- Differential backups operate in a similar manner as the incremental backups except for one key difference: differential backups archive data that have changed since the last full backup.
- For example, the same site in our previous example switches to differential backups. They lose data after the Wednesday differential backup. Now only two tapes are required for restoration: the Sunday full backup and the Wednesday differential backup.
Tape rotation methods
- A common tape rotation method is called FIFO (First In, First Out). Assume you are performing full daily backups and have 14 rewritable tapes in total.
- FIFO (also called round robin) means you will use each tape in order, and cycle back to the first tape after the 14th is used. This ensures 14 days of data is archived.
- The downside of this plan is you only maintain 2 weeks of data; this schedule is not helpful if you seek to restore a file that was accidentally deleted 3 weeks ago.
- Grandfather-Father-Son (GFS) addresses this problem.
- There are 3 sets of tapes: 7 daily tapes (the son), 4 weekly tapes (the father), and 12 monthly tapes (the grandfather).
- Once per week, a son tape graduates to father.
- Once every 5 weeks a father tape graduates to grandfather.
- After running for a year, this method ensures there are backup tapes available for the past 7 days, weekly tapes for the past 4 weeks, and monthly tapes for the past 12 months.
Electronic vaulting
- Electronic vaulting is the batch process of electronically transmitting data that is to be backed up on a routine, regularly scheduled time interval.
- It is used to transfer bulk information to an offsite facility.
- There are a number of commercially available tools and services that can perform electronic vaulting for an organisation.
- Electronic vaulting is a good tool for data that need to be backed up on a daily or possibly even hourly rate.
- It solves two problems at the same time: it stores sensitive data offsite and it can perform the backup at very short intervals to ensure that the most recent data is backed up.
Remote journalling
- A database journal contains a log of all database transactions. Journals may be used to recover from a database failure.
- Assume a database checkpoint (snapshot) is saved every hour. If the database loses integrity 20 min after a checkpoint, it may be recovered by reverting to the checkpoint and then applying all subsequent transactions described by the database journal.
- Remote journalling saves the database checkpoints and database journal to a remote site. In the event of failure at the primary site, the database may be recovered.
Database shadowing
- Database shadowing uses two or more identical databases that are updated simultaneously.
- The shadow database(s) can exist locally, but it is best practice to host one shadow database offsite.
- The goal of database shadowing is to greatly reduce the recovery time for a database implementation. Database shadowing allows faster recovery when compared with remote journalling.
High availabity (HA) options
- Increasingly, systems are being required to have effectively zero downtime, or an MTD of zero.
- The immediate availability of alternate systems is required should a failure or disaster occur. Recovery of data on tape is certainly ill equipped to meet these demands.
- A common way to achieve this level of uptime requirement is to employ a high availability cluster. The goal of a high availability cluster is to decrease the recovery time of a system or network device so that the availability of the service is less affected than it would be by having to rebuild, reconfigure, or otherwise stand up a replacement system.
- Two typical deployment approaches exist:
- An active-active cluster involves multiple systems, all of which are online and actively processing traffic or data. This configuration is also commonly referred to as load balancing and is especially common with public facing systems, such as Web server farms.
- An active-passive cluster involves devices or systems that are already in place, configured, powered on, and ready to begin processing network traffic should a failure occur on the primary system. Active-passive clusters are often designed such that any configuration changes made on the primary system or device are replicated to the standby system. Also, to expedite the recovery of the service, many failover cluster devices will automatically begin to process services on the secondary system should a disruption impact the primary device. It can also be referred to as a hot spare, standby, or failover cluster configuration.
DRP testing, training & awareness
- Testing, training, and awareness must be performed for the “disaster” portion of a BCP/DRP. Skipping these steps is one of the most common BCP/DRP mistakes.
- Some organisations “complete” their DRP, consider the matter resolved, and put the big DRP binder on a shelf to collect dust. This mentality is wrong on numerous levels.
- First, a DRP is never complete but is rather a continually amended method for ensuring the ability for the organisation to recover in an acceptable manner.
- Second, while well-meaning individuals carry out the creation and update of a DRP, even the most diligent of administrators will make mistakes. To find and correct these issues prior to their hindering recovery in an actual disaster, testing must be carried out on a regular basis.
- Third, any DRP that will be effective will have some inherent complex operations and manoeuvres to be performed by administrators.
- There will always be unexpected occurrences during disasters, but each member of the DRP should be exceedingly familiar with the particulars of their role in a DRP, which is a call for training on the process.
- Finally, it is important to be aware of the general user’s role in the DRP, as well as
the organisation’s emphasis on ensuring the safety of personnel and business operations in the event of a disaster.
DRP testing
- In order to ensure that a DRP represents a viable plan for recovery, thorough testing
is needed. - Given the DRP’s detailed tactical subject matter, it should come as no surprise that routine infrastructure, hardware, software, and configuration changes will alter the way the DRP needs to be carried out.
- Organisations’ information systems are in a constant state of flux, but unfortunately, much of these changes do not readily make their way into an updated DRP.
- To ensure both the initial and continued efficacy of the DRP as a feasible recovery methodology, testing needs to be performed.
- Each DRP testing method varies in complexity & cost, and simpler tests are less expensive. Here are the plans, ranked in order of cost & complexity, from low to high:
- DRP review
- Read-through/Checklist/Consistency
- Structured walkthrough/Tabletop
- Simulation test/Walkthrough drill
- Parallel processing
- Partial interruption
- Complete business interruption
- These are discussed in more detail below.
DRP review
- The DRP review is the most basic form of initial DRP testing and is focused on simply reading the DRP in its entirety to ensure completeness of coverage.
- It is typically performed by the team that developed the plan and will involve team members reading the plan in its entirety to quickly review the overall plan for any obvious flaws.
- The DRP review is primarily just a sanity check to ensure that there are no glaring omissions in coverage or fundamental shortcomings in the approach.
Read-through
- Read-through (also known as checklist or consistency) testing lists all necessary
components required for successful recovery and ensures that they are or will be
readily available should a disaster occur. - For example, if the disaster recovery plan calls for the reconstitution of systems from tape backups at an alternate computing facility, the site in question should have an adequate number of tape drives on hand to carry out the recovery in the indicated window of time.
- The read-through test is often performed concurrently with the structured walkthrough or tabletop testing as a solid first-testing threshold.
- The read-through test is focused on ensuring that the organisation has or can acquire in a timely fashion sufficient levels of resources upon which successful recovery is dependent.
Walkthrough
- Another test that is commonly completed at the same time as the checklist test is that of the walkthrough, which is also often referred to as a structured walkthrough or
tabletop exercise. - During this type of DRP test, which is usually performed prior to more in-depth testing, the goal is to allow individuals who are knowledgeable about the systems and services targeted for recovery to thoroughly review the overall approach.
- The term structured walkthrough is illustrative, as the group will discuss the proposed recovery procedures in a structured manner to determine whether there are any noticeable omissions, gaps, erroneous assumptions, or simply technical missteps that would hinder the recovery process from successfully occurring.
Simulation test
- A simulation test, also called a walkthrough drill (not to be confused with the
discussion-based structured walkthrough), goes beyond talking about the process
and actually has teams to carry out the recovery process. - A simulated disaster to which the team must respond as they are directed to by the DRP.
- As smaller disaster simulations are successfully managed, the scope of simulations will vary significantly and tend to grow more complicated and involve more systems.
Parallel processing
- Another type of DRP test is parallel processing. This type of test is common in environments where transactional data is a key component of the critical business processing.
- Typically, this test will involve recovery of critical processing components at an alternate computing facility and then restore data from a previous backup. Note
that regular production systems are not interrupted. - The transactions from the day after the backup are then run against the newly restored data, and the same results achieved during normal operations for the date in question should be mirrored by the recovery system’s results.
- Organisations that are highly dependent upon mainframe and midrange systems will often employ this type of test.
Partial & complete business interruption
- Arguably, the highest fidelity of all DRP tests involves business interruption testing.
However, this type of test can actually be the cause of a disaster, so extreme caution
should be exercised before attempting an actual interruption test. - As the name implies, the business interruption style of testing will have the organisation actually stop processing normal business at the primary location and will instead leverage the alternate computing facility.
- These types of tests are more common in organisations where fully redundant, often load-balanced operations already exist.
Continued BCP/DRP maintenance
- Once the initial BCP/DRP plan is completed, tested, trained, and implemented, it
must be kept up to date. - Business and IT systems change quickly, and IT professionals are accustomed to adapting to that change.
- BCP/DRP plans must keep pace with all critical business and IT changes.
Change management
- Change management includes tracking and documenting all planned changes, including formal approval for substantial changes and documentation of the results of the completed change.
- All changes must be auditable.
- The change control board manages the change management process; the BCP team should be a member and attend all meetings.
- The goal of the BCP team’s involvement on the change control board is to identify any changes that must be addressed by the BCP/DRP plan.
BCP/DRP mistakes
- BCP and DRP are a business’ final line of defence against failure. If other controls
have failed, BCP/DRP is the last resort. - The success of BCP/DRP is critical, but many plans fail. If it fails, the business may fail.
- The BCP team should consider the failure of other organisations’ plans and view their own procedures under intense scrutiny. They should ask themselves this question: “Have we made mistakes that threaten the success of our plan?”
- Common BCP/DRP mistakes include:
- Lack of management support
- Lack of business unit involvement
- Lack of prioritisation among critical staff
- Improper (often overly narrow) scope
- Inadequate telecommunications management
- Inadequate supply chain management
- Incomplete or inadequate CMP
- Lack of testing
- Lack of training and awareness
- Failure to keep the BCP/DRP plan up to date
Specific BCP/DRP frameworks
- Given the patchwork of overlapping terms and processes used by various BCP/DRP
frameworks, we have focused on universal best practices without attempting to
map to a number of different (and sometimes inconsistent) terms and processes described by various BCP/DRP frameworks. - However, a handful of specific frameworks are worth discussing, including NIST SP 800-34, ISO/IEC-27031, and BCI.
NIST SP 800-34
- The National Institute of Standards and Technology (NIST) Special Publication
800-34 Rev. 1 “Contingency Planning Guide for Federal Information Systems” is of high quality and is in the public domain. - Plans can sometimes be significantly improved by referencing SP 800-34 when writing or updating a BCP/DRP.
ISO/IEC 27031
- ISO/IEC 27031 is a new guideline that is part of the ISO 27000 series, which also
includes ISO 27001 and ISO 27002. - It’s designed to:
- Provide a framework (methods and processes) for any organisation—private, governmental, and non-governmental
- Identify and specify all relevant aspects including performance criteria, design, and implementation details for improving ICT (information & communications technology) readiness as part of the organisation’s ISMS (information security management system), helping to ensure business continuity
- Enable an organisation to measure its continuity, security and hence readiness to survive a disaster in a consistent and recognised manner.
- ISO/IEC 27031 focuses on BCP. A separate ISO plan for disaster recovery is ISO/IEC 24762.
BS-25999 & ISO 22301
- The British Standards Institution originally released BS-25999, which is in two parts:
- Part 1, the Code of Practice, provides business continuity management best
practice recommendations, and is a guidance document only. - Part 2, the Specification, provides the requirements for a Business Continuity
Management System (BCMS) based on BCM best practice. This is the part of
the standard that can be used to demonstrate compliance via an auditing and
certification process.
- Part 1, the Code of Practice, provides business continuity management best
- BS-25999-2 has been replaced with ISO 22301, which specifies the requirements for setting up and managing an effective BCMS for any organisation, regardless of type or size.
BCI
- The Business Continuity Institute (BCI) published a six-step Good Practice Guidelines (GPG) document
- They represent current global thinking in good BC practice and now include terminology from ISO 22301:2012, the International Standard for Business Continuity management systems.
- GPG 2013 describes six Professional Practices (PP):
- Management Practices
- PP1: Policy and Program Management
- PP2: Embedding Business Continuity
- Technical Practices
- PP3: Analysis
- PP4: Design
- PP5: Implementation
- PP6: Validation
- Management Practices
Summary of domain
- Operations security concerns the security of systems and data while being actively used in a production environment.
- Ultimately, operations security is about people, data, media, and hardware, all
of which are elements that need to be considered from a security perspective. - The best technical security infrastructure in the world will be rendered powerless if an individual with privileged access decides to turn against the organisation and there are no preventive or detective controls in place within it.
- We also discussed Business Continuity and Disaster Recovery Planning, which
serve as an organisation’s last control to prevent failure. - Of all controls, a failed BCP or DRP can be most devastating, potentially resulting in organisational failure, injury or even loss of life.
